
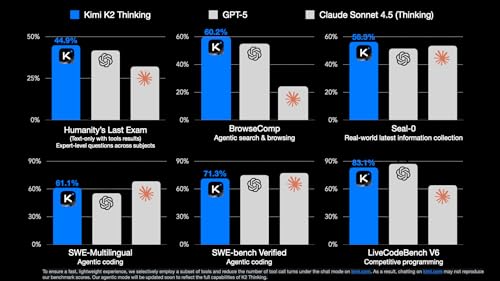
5 Thoughts on Kimi K2 Thinking
カートのアイテムが多すぎます
ご購入は五十タイトルがカートに入っている場合のみです。
カートに追加できませんでした。
しばらく経ってから再度お試しください。
ウィッシュリストに追加できませんでした。
しばらく経ってから再度お試しください。
ほしい物リストの削除に失敗しました。
しばらく経ってから再度お試しください。
ポッドキャストのフォローに失敗しました
ポッドキャストのフォロー解除に失敗しました

5 Thoughts on Kimi K2 Thinking
-
ナレーター:
-
著者:
このコンテンツについて
まだレビューはありません