
The AI Morning Read March 20, 2026 - One Token to See and Create: How CubiD Could Unify Vision AI
カートのアイテムが多すぎます
カートに追加できませんでした。
ウィッシュリストに追加できませんでした。
ほしい物リストの削除に失敗しました。
ポッドキャストのフォローに失敗しました
ポッドキャストのフォロー解除に失敗しました

The AI Morning Read March 20, 2026 - One Token to See and Create: How CubiD Could Unify Vision AI
-
ナレーター:
-
著者:
概要
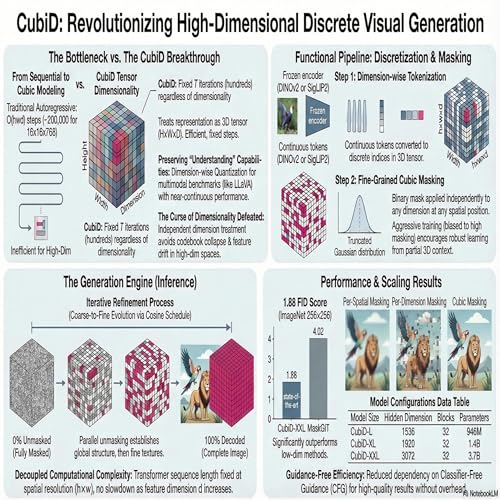
In today's podcast we deep dive into CubiD, or Cubic Discrete Diffusion, a groundbreaking new model that enables discrete visual generation using high-dimensional representation tokens. While previous discrete generative methods have been stuck using low-dimensional tokens that sacrifice essential semantic richness, CubiD successfully utilizes rich features with 768 to 1024 dimensions. It achieves this by treating the visual representation as a unified three-dimensional tensor and applying a novel, fine-grained masking technique independently across both its spatial and dimensional axes. This unique cubic masking approach transforms what would normally be an impossibly slow sequential modeling process into a highly efficient parallel generation that requires only a fixed number of steps, regardless of how high the dimensionality scales. Ultimately, by successfully preserving the semantic capabilities of these original features, CubiD proves that the exact same discrete tokens can be effectively used for both image understanding and image generation, paving the way for truly unified multimodal architectures.